Umlaut Technical Overview
To give you an overview of the technical architecture of umlaut, we will go through a typical Resolve request, identifying all the classes involved, and pointing to their api doc if possible.
OpenURLs are sent to the default index action of the resolve controller.
In the resolve controller, a before filter method called init_processing is run to parse the OpenURL and set up the Umlaut request (or retrieve an existing request).
Setting up the Request and it's context
OpenURL parsing and storing
In understanding Umlaut, it's helpful to understand a bit about the nature of an OpenURL, including that an OpenURL is composed of several entities or groupings of metadata. Jeff Young's Q6 blog includes one good explanation of the six OpenURL entities.
Two sets of classes are involved in dealing with OpenURLs in Umlaut. The ropenurl library is generally used to parse OpenURLs. However, Umlaut serializes OpenURLs to it's own ActiveRecord classes--Request, to represent an incoming OpenURL request, and some constituent data in Referrent, Referent Value, and Referrer.
Once the OpenURL is parsed with the ropenurl library, the data is stored in internal Umlaut classes, which are generally used subsequently to deal with the request data.
A bit confusingly, Umlaut's own Request (an ActiveRecord which represents a parsed OpenURL request, and other persistent state related to Umlaut's handling of that OpenURL request) should not be confused with the Rails ActionController::Request class (which represents the complete details of the current 'raw' HTTP request, and is not stored persistently in the db).
So the first thing the resolve action does is pass the incoming HTTP request details to the Umlaut Request#new_request method, which will 'either' create a new Request, or recover an already created Request from the db--in either case return a Request matching the OpenURL.
Request caching/re-use
The point of this re-use of Request objects is that if the user presses the browser reload button, the app should be connected with the same already created request--allowing the same already generated responses to be used, among other things. This also allows the user to click on various Umlaut functions and keep re-using the same Request. Again, the main reason this is important is to re-use already generated responses instead of re-generating them. This is also important for background service processing.
Cache matching for re-use is based on: Must be from the same session, must be from the same originating IP address, must have the same OpenURL elements (ie, same OpenURL parameters measured by a serialized version (Request#serialized_co_params)) stored in the 'params' attribute of Request.
Alternately, if the request ID is passed in (in query var "umlaut.request_id"), that is used instead of context object element matching. Umlaut often passes requestID internally, to make sure the same request is recovered. If request_id matches, sessions is not required to match--this is intentional to recover the request even if browser isn't returning cookies, thus not connecting to same session.
Building the service Collection: Institutions and Services
So we've got the request taken care of. What are we going to do with it?
Services
The actions taken in response to a request (to 'resolve' it and provide information to the client or user) are taken in umlaut by Services. A Service is defined in your local configuration in $umlaut/config/umlaut_config/services.yml. A sample services.yml file is included in $umlaut/config/umlaut_distribution/services.yml-dist.
Each service defined in services.yml has at minimum three properties: An unique identifier for that service, a priority level, and a "type".
The "type" is the name of an 'adaptor' class implementing the logic for this service. Service adaptor classes are stored in $umlaut/lib/service_adaptors. (We will extend this in the future to allow locally defined service_adaptors, perhaps in $umlaut/lib/service_adaptors/local ). So there's a service_adaptor for Amazon, for worldcat, etc. Most importantly, there's one for SFX---SFX connectivity is achieved through defining a service that uses a 'type' that talks to an SFX server , just like other services. (At least for 'resolve' actions; 'search' actions are a bit different).
Priority defines what order the services will be run in. 1-9 are foreground services ordinarily executed before a response is returned to the user. a-z are background services run after a response is returned to the user. Two services sharing the same priority will be run concurrently (but see the config.app_config.threaded_services config param).
Services defined in services.yml may have other service-specific parameters too, for instance commonly a password or api_key giving you access to the foreign web service.
Note that a Service is not actually an ActiveRecord stored in the db. Instead, it is a definition in services.yml, which involves an adaptor class (which is not an active record). Service definitions are loaded in on demand--and their adaptor classes instantiated--by the ServiceList singleton class.
For more on how to write service adaptor classes to implement new services, see.... TBD.
Institutions
Services are grouped together in Institutions. An Institution represents some particular class of user. It could be a particular location or affiliation, but it really could be any other class of user too.
Institutions are defined in $umlaut/config/umlaut_config/institutions.yml (sample in config/umlaut_distribution/institutions.yml-dist ). An Institution definition is basically a unique identifier and a list of services attached to that institution.
While Institutions are defined in the institution.yml config file, certain attributes of the Institution are ALSO stored in the database for quicker lookup (This may or may not make sense, but is a legacy design). After editing the institution.yml file, a rake task should be run to sync the info to the db too:
- rake umlaut:sync_institutions
The Insitution ActiveRecord automatically loads in properties stored in the institutions.yml, helped out by the InstitutionList store class.
Hypothetically, there will be many ways for a given incoming request to get associated with an Institution: by IP range, by user preference, by attribute from an enterprise directory associated with a user account, etc. An incoming user can be associated with one or more institutions.
However, at present, pretty much the only way for a user to be associated with an Institution is if it's a default Institution! So the only Institutions are default Institutions at present (there can be more than one default institution). This architecture has room for expansion.
Collection
So there are Services, and they are grouped into Institutions. How do they actually get brought into play to respond to a resolve request? The Collection object. A Collection keeps track of a bunch of services to be used for a given session.
The resolve index action creates a new Collection based on ip address and other session information. The new Collection will discover which Institutions apply to a user, and which Services belong to that Institution, and file them all by priority. Other Services may be found that do not belong to an Institution, for instance Collection is supposed to identify SFX servers for a user's IP addr via the Worldcat Registry, create a Service pointing to that foreign SFX server, and include that in a Collection. Although this functionality may not be working at present.
The Collection is stored in the Session. It is not actually an ActiveRecord, instead it is stored serialized in the Session--along with all it's Services. One catch to this is if you change Service configuration in services.yml, users may still be getting the old configuration from their serialized Collection in their Session. Deleting all Sessions is a good idea to handle this. (Deleting sessions ought not to interfere with anyone's activity in progress, except to uncache certain things).
The stored Collection will not be used if a user's IP address changes--even if they have the same session. For instance, bringing your laptop to a new location will still cause a Collection to be rebuilt.
When the resolve action wants to actually execute services, it goes through each priority level, and asks the Collection for the Services at that priority level.
ServiceResponse data and generation
Before talking about how the services generate data, we should talk about the data format of a ServiceResponse. A ServiceResponse is basically a unit of information generated by a Service, generally for display somewhere on the link resolver menu page. For example, there might be a ServiceResponse representing a fulltext link, a help link, or an abstract. ServiceResponses almost always link out somewhere, along with providing other data for display.
The ServiceResponse entity has a few 'standard' properties (display_text, url, notes), but also a property, service_data, consisting of a serialized hash for holding arbitrary key/value information. Different service types might require different key/values here. The [] operator on ServiceResponse conveniently allows you to store arbitrary key/value information in this property (and also access/set the 'built-in' properties). For appropriately loose coupling between data stored, service generating it, and view, we define some conventions for what key/value pairs are used for what purposes in each response type, in comments on ServiceResponse class definition.
A ServiceResponse also records which Service generated it, using that Service's service_id/name as defined in config/umlaut_config/services.yml, and generally retrievable from the ServiceList.
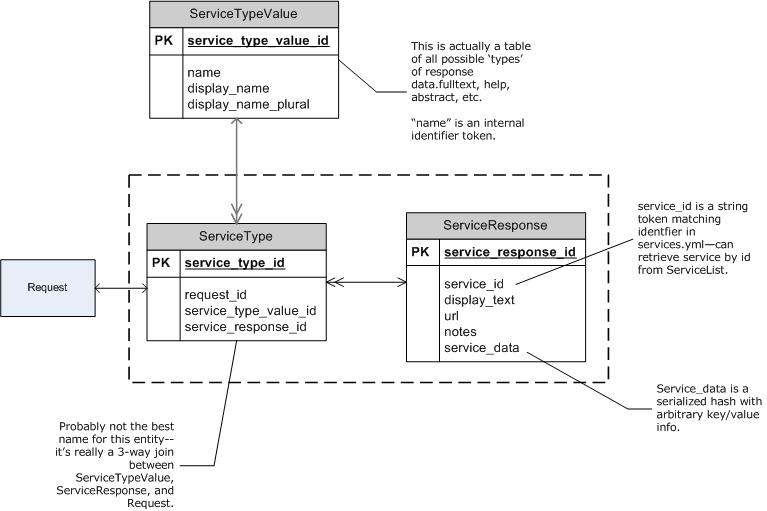
So what do we mean by a 'service type'? The list of all valid service types is defined in the ServiceTypeValue table. Each ServiceTypeValue has a one-word internal identifier token (name), a display_name for user presentation, and optionally a display_name_pluralized (to over-ride standard Rails pluralization). The values in this table are initialized from db/orig_fixed_data/service_type_values.yml when you run rake umlautdb:load_initial_data. We intend the local implementer to be able to create locally defined ServiceTypeValues too, if necessary.
ServiceTypeValue uses the acts_as_enumerated plug-in to conveniently allow the developer to refer to an individual ServiceTypeValue by name: ServiceTypeValue[:fulltext] ==> the ServiceTypeValue object with name == 'fulltext'. acts_as_plugin does efficient caching.
So obviously which ServiceTypeValue a given ServiceResponse is intended for needs to be registered somewhere. But you won't find it in ServiceResponse, which might be confusing at first. In fact, there's a somewhat confusingly named three-way join object called ServiceType, which ties together:
- a ServiceResponse
- a ServiceTypeValue
- a Request
This architecture theoretically allows:
- One ServiceResponse to belong to multiple Requests (ServiceResponse cacheing accross requests/sessions).
- One ServiceResponse to be assigned multiple ServiceTypeValues and thus listed multiple times with a given Request.
In fact, Umlaut does not currently use ServiceResponse caching across requests; it turned out to be tricky to get right without clear gain. And very few (if any?) current services register the same ServiceResponse to a request with multiple ServiceTypeValues. But, the architecture is there to support it if needed in the future.
This data structure architecture ends up somewhat confusing (and ServiceType is probably not a clear name for that three-way join) but there are usually convenience methods defined to avoid the complexity; they should be used. See for example (tbd).
Data structure diagram Trying to figure out how to make this display inline, sorry.
{kind=link}
Obligations of Service logic
What you need to know to write a new Service. How to generate data, and callback methods service logic can or must provide.
Recall that an umlaut "service" is defined in config/umlaut_config/services.yml to be a particular class holding the service logic, and some configuration parameters.
That class holding the service logic is called a "service adaptor", or somewhat ambiguously, sometimes times just a "service". Service adaptors live in lib/service_adaptors, and extend Service.
Service adaptor implementation
Statelessness
Service logic should generally be written to be state-less. The same Service object, defined in services.yml, is initialized once and generally re-used for the life of an application instance (cached by ServiceList). So any state you store can end up persisting from request to request and session to session, which you probably don't intend. Umlaut architecture for background services also involves threads and forks, and while there's normally no reason a given service object would be in two threads simultaneously, better safe than sorry. It's safest to store no non-universal state in the service object.
Disclosure methods
A service adaptor must define service_types_generated() to return an Array of ServiceTypeValues constituting the types of ServiceResponses the service
A service adaptor may optionally list some required configuration params. If they are not supplied, an exception will be thrown when the service is initialized from services.yml. eg:
- required_config_params :api_key, :base_url
The handle method
The heart of a typical service is in implementing the handle method. When Umlaut wants a service to do it's thing, Umlaut will pass the request in, and it's up to the Service to do it's work.
The service can examine all metadata from the request, and even examine ServiceResponses generated by other services, and the status of other services in progress or finished. (See Request#dispatched_services, Request#dispatched, Request#services_in_progress, etc.)